Section 15.1 Investigation 3.5: Dolphin Therapy
Exercises 15.1.1 The Study

Antonioli and Reveley (2005) investigated whether swimming with dolphins was therapeutic for patients suffering from clinical depression. The researchers recruited 30 subjects aged 18-65 with a clinical diagnosis of mild to moderate depression through announcements on the internet, radio, newspapers, and hospitals in the U.S. and Honduras. Subjects were required to discontinue use of any antidepressant drugs or psychotherapy four weeks prior to the experiment, and throughout the experiment. These 30 subjects went to an island off the coast of Honduras, where they were randomly assigned to one of two treatment groups. Both groups engaged in one hour of swimming and snorkeling each day, but one group (Dolphin Therapy) did so in the presence of bottlenose dolphins and the other group (Control) did not. At the end of two weeks, each subject’s level of depression was evaluated, as it had been at the beginning of the study, and each subject was categorized as experiencing substantial improvement in their depression symptoms or not. (Afterwards, the control group had 1-day session with the dolphins.)
2. Study Type.
Was this an observational study or an experiment? Explain how you are deciding.
The following two-way table summarizes the results of this experiment:
| Improvement? \ Treatment | Dolphin Therapy | Control Group | Total |
|---|---|---|---|
| Showed substantial improvement | 10 | 3 | 13 |
| Did not show substantial improvement | 5 | 12 | 17 |
| Total | 15 | 15 | 30 |
3. For Practice.
4. Calculate Difference in Proportions.
5. Initial Assessment.
Do the data appear to support the claim that dolphin therapy is more effective than the control program?
6. Alternative Explanation.
Suppose swimming with dolphins is no more effective than swimming alone. What could be another possible explanation for the difference in these two sample proportions?
We must ask the same questions we have asked before – is it possible that this difference has arisen by random chance alone if there was no effect of the dolphin therapy? If so, how surprising would it be to observe such an extreme difference between the two groups?
One way to define a parameter in this case is to let \(\pi_{dolphin} - \pi_{control}\) denote the difference in the underlying probability of substantial improvement between the two treatment conditions.
7. State Hypotheses.
8. Design Simulation.
So under the null hypothesis, we are assuming that there is no difference in the treatment effect between the two treatments. In other words, whether or not people improved is not related to which group they are put in. Explain how you could design a simulation to help address this question, keeping in mind that this study involved random assignment not random sampling. Also keep in mind that this simulation will assume the null hypothesis is true.
One way to model this situation is by assuming 13 of the 30 people were going to demonstrate substantial improvement regardless of whether they swam with or without dolphins. Then the key question is how unlikely is it for the random assignment process alone to randomly place 10 or more of these 13 improvers into the dolphin therapy group (that is, a difference in the conditional proportions that improve of 0.467 or larger)? If the answer is that this observed difference would be very surprising if the dolphin and control therapies were equally effective, then we would have strong evidence to conclude that dolphin therapy is more effective.
To model the chance variability inherent in the random assignment process, under the null hypothesis,
-
Take a set of 30 playing cards or index cards, one for each participant in the study.
-
Designate 13 of them to represent improvements (e.g., red suited cards, blue colored index cards, or S-labeled index cards) and then mark 17 of them to represent non-improvements (e.g., black suited cards, green colored index cards, or F-labeled index cards).
-
Shuffle the cards and deal out two groups: 15 of the "subjects" to the dolphin therapy group and 15 to the control group.
9. Physical Simulation.
Complete the following two-way table to show your "could have been" result under the null hypothesis.
Simulation Repetition #1:
| Improved? \ Treatment | Dolphin Therapy | Control Group | Total |
|---|---|---|---|
| Showed substantial improvement | 13 (blue) | ||
| Did not show substantial improvement | 17 (green) | ||
| Total | 15 | 15 | 30 |
Also calculate the difference in the conditional proportions (dolphin – control) from this first simulated repetition, and indicate whether this simulated result is as extreme as the observed result:
10. Additional Repetitions.
Repeat this hypothetical random assignment two more times and record the "could have been" tables:
Repetition 2:
| Improved? \ Treatment | Dolphin | Control |
|---|---|---|
| Yes | ||
| No |
Repetition 3:
| Improved? \ Treatment? | Dolphin | Control |
|---|---|---|
| Yes | ||
| No |
Note: You may have noticed that once you entered the number of improvers in the Dolphin Group into the table, the other entries in the table were pre-determined due to the "fixed margins." So for our statistic, we could either report the difference in the conditional proportions or the number of successes (improvers) in the Dolphin group as these give equivalent information.
Aside: Randomization Animation.
Pool your results for the number of successes (blue index cards) assigned to the Dolphin Group for your 3 repetitions with the rest of your class and produce a well-labeled dotplot of the null distribution.
11. Interpret Dotplot.
Solution.
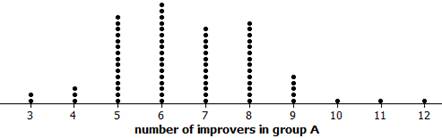
12. Preliminary Assessment.
Granted, we have not done an extensive number of repetitions, but how’s it looking so far? Does it seem like the actual experimental results (the observed 10/3 split) would be surprising to arise purely from the random assignment process under the null hypothesis that dolphin therapy is not effective? Explain.
We really need to do this simulated random assignment process hundreds, preferably thousands of times. This would be very tedious and time-consuming with cards, so let’s turn to technology.
Using the Dolphin Study applet.
-
Confirm that the two-way table displayed by the applet matches that of the research study.
-
Check Show Shuffle Options and confirm that there are 30 total "people": 13 blue and 17 green.
-
If viewing applet here, you can check the Hide Left Panel box in the lower right. Uncheck the box when you want to see the left panel again.
-
-
Press Shuffle.
Watch as the applet repeats what you did: Shuffle the 30 cards and deal out 15 for the "Dolphin therapy" group, separating blue cards (successes) from green cards (failures), and 15 for the "Control Group"; create the table of "could have been" simulated results; add a dot to the dotplot for the number of improvers (blue cards) randomly assigned to the "Dolphin therapy" group (GroupA successes).
-
Now press Shuffle four more times.
13. Repeating the random shuffling.
Does the number of successes vary among the repetitions?
-
Enter 995 for the Number of Shuffles.
This produces a total of 1,000 repetitions of the simulated random assignment process under the null hypothesis (the "null distribution" or a "randomization distribution").
14. Null Distribution.
What is the value of the mean of this null distribution? Explain why this center makes intuitive sense.
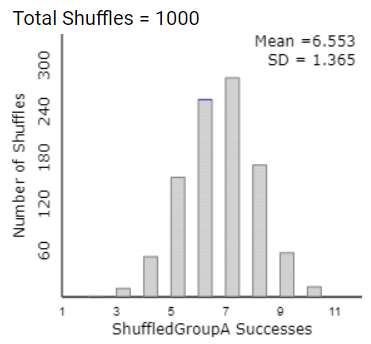
15. Compare to Observed Result.
Now we want to compare the observed result from the research study to these "could have been" results under the null hypothesis.
How many improvers were there in the Dolphin therapy group in the actual study?
Based on the resulting dotplot, does it seem like the actual experimental results would be surprising to arise solely from the random assignment process under the null hypothesis that dolphin therapy is not effective? Explain.
-
In the Count Samples box, enter the observed statistic from the actual study and press Count to have the applet count the number of repetitions with 10 or more successes in the Dolphin group.
16. Calculate p-value.
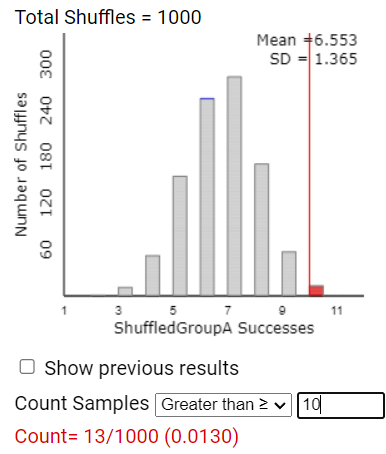
We said above that it would be equivalent to look at the difference in the conditional proportions.
-
Use the Statistic pull-down menu to select Difference in proportions.
17. Difference in Proportions.
Solution.
18. Interpret p-value.
19. Strength of Evidence.
Is this empirical p-value small enough to convince you that the experimental data that the researchers obtained provide strong evidence that dolphin therapy is effective (i.e., that the null hypothesis is not correct)?
20. Confounding Variables.
Is it reasonable to attribute the observed difference in success proportions to the dolphin therapy, or could the difference be due to a confounding variable? Explain.
21. Generalizability.
To what population is it reasonable to generalize these results? Justify your answer.
Discussion.
This procedure of randomly reassigning the response variable outcomes to the explanatory variable groups is often called a "randomization test." The goal is to assess the chance variability from the random assignment process (as opposed to random sampling), though it is sometimes used to approximate the random chance arising from random sampling as well. Use of this procedure models the two-way table with fixed row and column totals (e.g., people were going to improve or not regardless of which treatment they received).
Study Conclusions.
Due to the small p-value (0.01 < p-value < 0.05) from our "randomization test," we have moderately strong evidence that "luck of the draw" of the random assignment process alone is not a reasonable explanation for the higher proportion of subjects who substantially improved in the dolphin therapy group compared to the control group. Thus the researchers have moderate evidence that subjects aged 18–65 with a clinical diagnosis of mild to moderate depression (who would apply for such a study and fit the inclusion criteria) will have a higher probability of substantially reducing their depression symptoms if they are allowed to swim with dolphins rather than simply visiting and swimming in Honduras. Because this was a randomized comparative experiment, we can conclude that there is moderately strong evidence that swimming with dolphins causes a higher probability of experiencing substantial improvement in depression symptoms. But with this volunteer sample, we should be cautious about generalizing this conclusion beyond the population of people suffering from mild-to-moderate depression who could afford to take the time to travel to Honduras for two weeks.
Subsection 15.1.2 Practice Problem 3.5A
A 2010 study compared two groups: One group was reminded of the sacrifices that physicians have to make as part of their training, and the other group was given no such reminder. All physicians in the study were then asked whether they consider it acceptable for physicians to receive free gifts from industry representatives. It turned out that 57/120 in the "sacrifice reminders" group answered that gifts are acceptable, compared to 13/60 in the "no reminder" group.
Checkpoint 15.1.1. Identify Variables.
Identify the explanatory and response variables in this study.
Checkpoint 15.1.2. Random Assignment.
Do you believe this study used random assignment? What would that involve?
Checkpoint 15.1.3. Random Sampling.
Do you believe this study used random sampling? What would that involve?
Checkpoint 15.1.4. Simulation Analysis.
Checkpoint 15.1.5. Unequal Sample Sizes.
A colleague points out that the sample sizes are not equal in this study, so we can’t draw meaningful conclusions. How should you respond?
Subsection 15.1.3 Practice Problem 3.5B
Checkpoint 15.1.6. Two-Sided p-value.
How would you find a two-sided p-value for the dolphin study?
You have attempted of activities on this page.
