
5.12. El ordenamiento rápido¶
El ordenamiento rápido usa dividir y conquistar para obtener las mismas ventajas que el ordenamiento por mezcla, pero sin utilizar almacenamiento adicional. Sin embargo, es posible que la lista no se divida por la mitad. Cuando esto sucede, veremos que el desempeño disminuye.
Un ordenamiento rápido primero selecciona un valor, que se denomina el valor pivote. Aunque hay muchas formas diferentes de elegir el valor pivote, simplemente usaremos el primer ítem de la lista. El papel del valor pivote es ayudar a dividir la lista. La posición real a la que pertenece el valor pivote en la lista final ordenada, comúnmente denominado punto de división, se utilizará para dividir la lista para las llamadas posteriores a la función de ordenamiento rápido.
La Figura 12 muestra que 54 servirá como nuestro primer valor pivote. Como ya hemos visto este ejemplo unas cuantas veces, sabemos que 54 eventualmente terminará en la posición que actualmente contiene a 31. El proceso de partición sucederá a continuación. Encontrará el punto de división y al mismo tiempo moverá otros ítems al lado apropiado de la lista, según sean menores o mayores que el valor pivote.

Figura 12: El primer valor pivote para un ordenamiento rápido¶
Figura 12: El primer valor pivote para un ordenamiento rápido
El particionamiento comienza localizando dos marcadores de posición -llamémoslos marcaIzq y marcaDer- al principio y al final de los ítems restantes de la lista (posiciones 1 y 8 en la Figura 13). El objetivo del proceso de partición es mover ítems que están en el lado equivocado con respecto al valor pivote mientras que también se converge en el punto de división. La Figura 13 muestra este proceso a medida que localizamos la posición del 54.
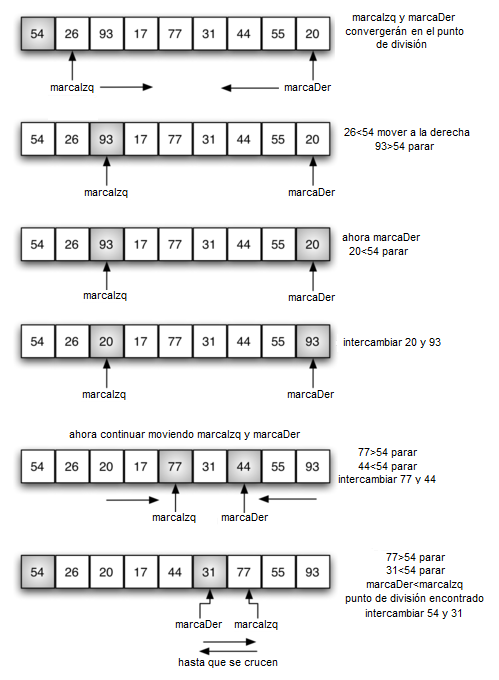
Figura 13: Encontrar el punto de división para el 54¶
Figura 13: Encontrar el punto de división para el 54
Comenzamos incrementando marcaIzq hasta que localicemos un valor que sea mayor que el valor pivote. Luego decrementamos marcaDer hasta que encontremos un valor que sea menor que el valor pivote. En tal punto habremos descubierto dos ítems que están fuera de lugar con respecto al eventual punto de división. Para nuestro ejemplo, esto ocurre en 93 y 20. Ahora podemos intercambiar estos dos ítems y luego repetir el proceso de nuevo.
Nos detendremos en el punto donde marcaDer se vuelva menor que marcaIzq. La posición de marcaDer es ahora el punto de división. El valor pivote se puede intercambiar con el contenido del punto de división y el valor pivote está ahora en su lugar (Figura 14). Además, todos los ítems a la izquierda del punto de división son menores que el valor pivote y todos los ítems a la derecha del punto de división son mayores que el valor pivote. La lista ahora se puede dividir en el punto de división y el ordenamiento rápido se puede invocar recursivamente para las dos mitades.
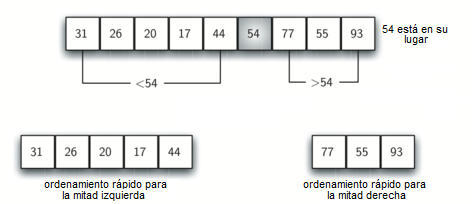
Figura 14: Finalización para completar el proceso de partición para encontrar el punto de división para 54¶
Figura 14: Finalización para completar el proceso de partición para encontrar el punto de división para 54
La función ordenamientoRapido mostrada en el ActiveCode 1 invoca una función recursiva, ordenamientoRapidoAuxiliar. La función ordenamientoRapidoAuxiliar comienza con el mismo caso base que el ordenamiento por mezcla. Si la longitud de la lista es menor o igual a uno, ya está ordenada. Si es mayor, entonces puede ser particionada y ordenada recursivamente. La función particion implementa el proceso descrito anteriormente.
Para analizar la función ordenamientoRapido, tenga en cuenta que para una lista de longitud n, si la partición siempre ocurre en el centro de la lista, habrá de nuevo \(\log n\) divisiones. Con el fin de encontrar el punto de división, cada uno de los n ítems debe ser comparado contra el valor pivote. El resultado es \(n\log n\). Además, no hay necesidad de memoria adicional como en el proceso de ordenamiento por mezcla.
Lamentablemente, en el peor de los casos, los puntos de división pueden no estar en el centro y podrían estar muy sesgados a la izquierda o a la derecha, dejando una división muy desigual. En este caso, ordenar una lista de n ítems se divide en ordenar una lista de 0 ítems y una lista de \(n-1\) ítems. Similarmente, ordenar una lista de tamaño \(n-1\) se divide en una lista de tamaño 0 y una lista de tamaño \(n-2\) y así sucesivamente. El resultado es un ordenamiento \(O(n^{2})\) con toda la sobrecarga que requiere la recursión.
Mencionamos anteriormente que hay diferentes maneras de elegir el valor pivote. En particular, podemos tratar de aliviar algunas de las posibilidades de una división desigual mediante el uso de una técnica denominada mediana de tres. Para elegir el valor pivote, consideraremos el primer ítem, el ítem medio y el último ítem de la lista. En nuestro ejemplo, son 54, 77 y 20. Ahora escogemos el valor de la mediana, en nuestro caso 54, y lo usamos para el valor pivote (por supuesto, ése era el valor pivote que utilizamos originalmente). La idea es que en caso que el primer ítem de la lista no pertenezca al centro de la lista, la mediana de tres elegirá un mejor valor “central”. Esto será particularmente útil cuando la lista original ya está algo ordenada al comenzar. Dejamos la implementación de esta selección de valores pivote como ejercicio.
Autoevaluación
- [9, 3, 10, 13, 12]
- Es importante recordar que el ordenamiento rápido opera sobre toda la lista y la ordena sin requerir almacenamiento adicional.
- [9, 3, 10, 13, 12, 14]
- Es importante recordar que el ordenamiento rápido opera sobre toda la lista y la ordena sin requerir almacenamiento adicional.
- [9, 3, 10, 13, 12, 14, 17, 16, 15, 19]
- El primer particionamiento opera sobre toda la lista, y el segundo particionamiento opera sobre la partición izquierda no sobre la derecha.
- [9, 3, 10, 13, 12, 14, 19, 16, 15, 17]
- El primer particionamiento opera sobre toda la lista y el segundo particionamiento opera sobre la partición izquierda.
Q-3: Dada la siguiente lista de números [14, 17, 13, 15, 19, 10, 3, 16, 9, 12] ¿Cuál respuesta corresponde al contenido de la lista después de la segunda partición de acuerdo al algoritmo de ordenamiento rápido?
- 1
- Los tres números utilizados en la selección del pivote son 1, 9, 19. El 1 no es la mediana, y sería una muy mala elección para el pivote ya que es el número más pequeño de la lista.
- 9
- Bien hecho.
- 16
- Aunque 16 sería la mediana de 1, 16, 19 el centro está en len(lista) // 2.
- 19
- Los tres números utilizados en la selección del pivote son 1, 9, 19. El 9 es la mediana. El 19 sería una mala elección ya que es casi el mayor valor.
Q-4: Dada la siguiente lista de números [1, 20, 11, 5, 2, 9, 16, 14, 13, 19] ¿Cuál sería el primer valor pivote usando el método de la mediana de tres?
- Ordenamiento de Shell
- El ordenamiento de Shell sort es aproximadamente ``n^1.5``
- Ordenamiento rápido
- El ordenamiento rápido puede ser O(n log n), pero si los puntos pivote no son bien escogidos y la lista está cuidadosamente arreglada, puede ser O(n^2).
- Ordenamiento por mezcla
- El ordenamiento por mezcla es el único con garantía de ser O(n log n) aún en el peor caso. El costo es que el ordenamiento por mezcla usa más memoria.
- Ordenamiento por inserción
- El ordenamiento por inserción es ``O(n^2)``
Q-5: ¿Cuál de los siguientes algoritmos de ordenamiento tienen garatía de ser O(n log n) aún en el peor caso?