
5.11. El ordenamiento por mezcla¶
Ahora dirigimos nuestra atención a usar una estrategia de dividir y conquistar como una forma de mejorar el desempeño de los algoritmos de ordenamiento. El primer algoritmo que estudiaremos es el ordenamiento por mezcla. El ordenamiento por mezcla es un algoritmo recursivo que divide continuamente una lista por la mitad. Si la lista está vacía o tiene un solo ítem, se ordena por definición (el caso base). Si la lista tiene más de un ítem, dividimos la lista e invocamos recursivamente un ordenamiento por mezcla para ambas mitades. Una vez que las dos mitades están ordenadas, se realiza la operación fundamental, denominada mezcla. La mezcla es el proceso de tomar dos listas ordenadas más pequeñas y combinarlas en una sola lista nueva y ordenada. La Figura 10 muestra nuestra lista de ejemplo familiar a medida que está siendo dividida por ordenamientoPorMezcla. La Figura 11 muestra las listas simples, ahora ordenadas, a medida que se fusionan de nuevo.
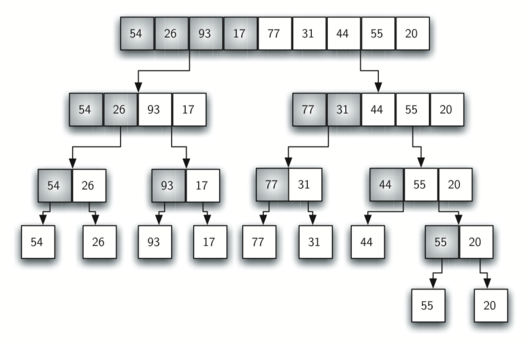
Figura 10: División de la lista en un ordenamiento por mezcla¶
Figura 10: División de la lista en un ordenamiento por mezcla
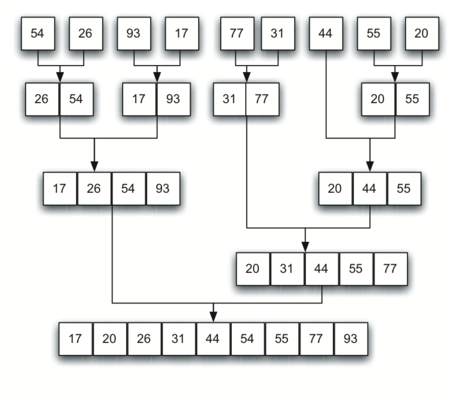
Figura 11: Listas a medida que se fusionan de nuevo¶
Figura 11: Listas a medida que se fusionan de nuevo
La función ordenamientoPorMezcla mostrada en el ActiveCode 1 comienza preguntando por el caso base. Si la longitud de la lista es menor o igual a uno, entonces ya tenemos una lista ordenada y no es necesario más procesamiento. Si, por otro lado, la longitud es mayor que uno, entonces usamos la operación slice de Python para extraer las mitades izquierda y derecha. Es importante tener en cuenta que la lista podría no tener un número par de ítems. Eso no importa, ya que las longitudes serán diferentes a lo sumo en uno.
Una vez que se invoca la función ordenamientoPorMezcla en la mitad izquierda y la mitad derecha (líneas 8-9), se asume que están ordenadas. El resto de la función (líneas 11-31) es responsable de mezclar las dos listas ordenadas más pequeñas en una lista ordenada más grande. Observe que la operación de mezcla ubica los ítems de nuevo en la lista original (unaLista) uno a la vez tomando repetidamente el ítem menor de las listas ordenadas.
La función ordenamientoPorMezcla se ha aumentado con una instrucción print (línea 2) para mostrar el contenido de la lista que se está ordenando al inicio de cada invocación. También hay una instrucción print (línea 32) para mostrar el proceso de mezcla. La impresión muestra el resultado de la ejecución de la función con nuestra lista de ejemplo. Note que la lista con los ítems 44, 55 y 20 no se dividirá en partes iguales. La primera división da [44] y la segunda da [55,20]. Es fácil ver cómo el proceso de división eventualmente produce una lista que se puede mezclar inmediatamente con otras listas ordenadas.
Para analizar la función ordenamientoPorMezcla, debemos considerar los dos procesos distintos que conforman su implementación. En primer lugar, la lista se divide en mitades. Ya calculamos (en una búsqueda binaria) que podemos dividir una lista por la mitad en un tiempo \(\log n\) donde n es la longitud de la lista. El segundo proceso es la mezcla. Cada ítem de la lista se procesará y se colocará en la lista ordenada. Así que la operación de mezcla que da lugar a una lista de tamaño n requiere n operaciones. El resultado de este análisis es que se hacen \(\log n\) divisiones, cada una de las cuales cuesta \(n\) para un total de \(n\log n\) operaciones. Un ordenamiento por mezcla es un algoritmo \(O(n\log n)\).
Recuerde que el operador de partición es \(O(k)\) donde k es el tamaño de la partición. Para garantizar que ordenamientoPorMezcla sea \(O(n\log n)\) tendremos que quitar el operador de partición. Una vez más, esto es posible si simplemente pasamos los índices inicial y final junto con la lista cuando hacemos la llamada recursiva. Dejamos esto como ejercicio.
Es importante notar que la función ordenamientoPorMezcla requiere espacio adicional para almacenar las dos mitades a medida que se extraen con las operaciones de partición. Este espacio adicional puede ser un factor crítico si la lista es grande y puede tornar problemático a este ordenamiento cuando se trabaja sobre grandes conjuntos de datos.
Autoevaluación
- [16, 49, 39, 27, 43, 34, 46, 40]
- Ésta es la segunda mitad de la lista.
- [21,1]
- Sí, ordenamientoPorMezcla continuará moviéndose recursivamente hacia el inicio de la lista hasta que se tope con el caso base.
- [21, 1, 26, 45]
- Recuerde que ordenamientoPorMezcla no opera sobre la mitad derecha de la lista sino hasta que la mitad derecha esté completamente ordenada.
- [21]
- Ésta es la lista después de 4 llamadas recursivas
Q-3: Dada la siguiente lista de números: [21, 1, 26, 45, 29, 28, 2, 9, 16, 49, 39, 27, 43, 34, 46, 40] ¿Cuál de las siguientes respuestas corresponde a la lista que será ordenada después de 3 llamadas recursivas a ordenamientoPorMezcla?
- [21, 1] y [26, 45]
- Las primeras dos listas mezcladas serán listas de caso base, aún no hemos alcanzado un caso base.
- [[1, 2, 9, 21, 26, 28, 29, 45] y [16, 27, 34, 39, 40, 43, 46, 49]
- Éstas serán las dos últimas listas mezcladas
- [21] y [1]
- Las listas [21] y [1] son los dos primeros casos base encontrados por ordenamientoPorMezcla y, por tanto, serán las dos primeras listas mezcladas.
- [9] y [16]
- Aunque 9 y 16 son valores vecinos, están en mitades diferentes de la lista desde la primera partición.
Q-4: Dada la siguiente lista de números: [21, 1, 26, 45, 29, 28, 2, 9, 16, 49, 39, 27, 43, 34, 46, 40] ¿Cuál de las siguientes respuestas corresponde a las primeras dos listadas que serán mezcladas?